Thought process for designing a Geospatial algorithm using postgis (code included)
⌛ 3 years ago | 📖 9 min read
So few months ago NAXA Pvt. Ltd., Kathmandu Living Labs, Nepal Geomatics Engineering Society, Humanitarian OpenStreetMap Team and Open Mapping Hub - Asia Pacific jointly organized a Hackathon for Field-mapping Task Splitting algorithm. Our team of 3 participated in this awesome event and fortunately our team "Bug Developers" 🎉 won 🎉 the competition. This article is about what went through our mind while designing the winning algorithm and how we implemented it.
If you want to jump directly into the code then you can find it in this Github Repo
While mappers collect data in field using tools like ODK then dividing the field area becomes a challenging task. There are multiple factors to be considered like distance between survey points, barriers like highways and river, workload distribution among mappers and so on. Hence, designing a efficient algorithm to do this task efficiently is a challenge in itself. Our task was to purpose a best possible solution to these problems. Our final output would be classification algorithm than can classify buildings into survey areas while taking above mentioned factors into consideration.
- PostGis (For manipulating Geo-spatial data and writing algorithm)
- Python with pandas and matplotlib (Visualizing the results of algorithm)
Now lets look at the whole algorithm and then break it down to understand better. I will be describing the actual algorithm written in SQL. For complete solution with python code you may refer to the repository. Here is the algorithm as a whole.
/* Filtering barriers by tags */ WITH islington_lines_filtered AS ( SELECT geom, osm_id, tags FROM islington_lines WHERE tags->>'highway' NOT IN ('footway','residential','service','path','cycleway','pedestrian','steps','track','unclassified') AND (tags->>'highway' IS NOT NULL OR tags->>'waterway' IS NOT NULL OR tags->>'railway' IS NOT NULL) ), /* Clipping barriers to the AOI */ islington_lines_clipped AS ( SELECT ST_Intersection(a.geom, l.geom) AS geom, l.osm_id, l.tags FROM islington_aoi a, islington_lines_filtered l WHERE ST_Intersects(a.geom, l.geom) ), /* Polygonizing filtered barrier features */ islington_cluster_polygons AS ( SELECT (ST_Dump(ST_Polygonize(ST_Node(geom)))).geom FROM ( SELECT islington_lines_filtered.geom AS geom FROM islington_lines_filtered ) q ), /* Adding an id to each polygon */ islington_cluster_polygons_with_id AS ( SELECT ROW_NUMBER() OVER (ORDER BY islington_cluster_polygons.geom) polygon_id, islington_cluster_polygons.geom FROM islington_cluster_polygons, islington_aoi ), /* Centroid of each building */ islington_polygons_centroids AS ( SELECT st_centroid(geom) as geom, osm_id FROM islington_polygons WHERE tags->>'building'='yes' ), /* Clipping buildings to the AOI */ islington_polygons_centroids_clipped AS ( SELECT ST_Intersection(a.geom, p.geom) AS geom, p.osm_id FROM islington_aoi a, islington_polygons_centroids p WHERE ST_Intersects(a.geom, p.geom) ), /* Grouping buildings by their zone (barrier polygons) */ islington_polygons_centroids_grouped AS ( SELECT islington_cluster_polygons_with_id.polygon_id as polygon_id , islington_polygons_centroids_clipped.geom as geom, islington_polygons_centroids_clipped.osm_id as osm_id FROM islington_polygons_centroids_clipped LEFT JOIN islington_cluster_polygons_with_id ON ST_Within(islington_polygons_centroids_clipped.geom, islington_cluster_polygons_with_id.geom) ), /* Clustering buildings centroids based on their zone (barrier polygons) */ islington_polygons_centroids_clustered AS ( SELECT ST_ClusterKMeans(geom, 7) over(PARTITION BY polygon_id) AS cid, geom, osm_id, islington_polygons_centroids_grouped.polygon_id FROM islington_polygons_centroids_grouped ) /* Selecting and displaying clustered centroids */ SELECT * FROM islington_polygons_centroids_clustered ;
Now that is a big chunk of SQL 😰 but don't be intimidated. We shall break it down and understand it.
Identifying the barriers
/* Filtering barriers by tags */ WITH islington_lines_filtered AS ( SELECT geom, osm_id, tags FROM islington_lines WHERE tags->>'highway' NOT IN ('footway','residential','service','path','cycleway','pedestrian','steps','track','unclassified') AND (tags->>'highway' IS NOT NULL OR tags->>'waterway' IS NOT NULL OR tags->>'railway' IS NOT NULL) ),
First thing we do is identify barriers. Our main goal is that mappers should not bear the hassle of crossing Big highways, rivers or railways. Also, as you see we are not taking small roads like footway, residental etc as barriers. Mappers are able to cross these paths and in fact would be good if one mapper would survey both sides of a footway.
Preparing the barriers
/* Clipping barriers to the AOI */ islington_lines_clipped AS ( SELECT ST_Intersection(a.geom, l.geom) AS geom, l.osm_id, l.tags FROM islington_aoi a, islington_lines_filtered l WHERE ST_Intersects(a.geom, l.geom) ), /* Polygonizing filtered barrier features */ islington_cluster_polygons AS ( SELECT (ST_Dump(ST_Polygonize(ST_Node(geom)))).geom FROM ( SELECT islington_lines_filtered.geom AS geom FROM islington_lines_filtered ) q ), /* Adding an id to each polygon */ islington_cluster_polygons_with_id AS ( SELECT ROW_NUMBER() OVER (ORDER BY islington_cluster_polygons.geom) polygon_id, islington_cluster_polygons.geom FROM islington_cluster_polygons, islington_aoi ),
First we clip the barriers to area of interest(which is a polygon boundary of our mapping area). Second, we polygonize these barriers. Which means that we simply convert these barrier lines to enclosed polygons. This will be necessary later for our classification. Third, we assign unique ids to the polygonized barriers. Now, our polygons are ready for some clipping action.
Getting the Buildings Ready
/* Centroid of each building */ islington_polygons_centroids AS ( SELECT st_centroid(geom) as geom, osm_id FROM islington_polygons WHERE tags->>'building'='yes' ), /* Clipping buildings to the AOI */ islington_polygons_centroids_clipped AS ( SELECT ST_Intersection(a.geom, p.geom) AS geom, p.osm_id FROM islington_aoi a, islington_polygons_centroids p WHERE ST_Intersects(a.geom, p.geom) ),
First, we take centroids for each building polygon. Why? you may ask. We do not want a building that is half in between twoclusters as it creates ambiguity and there may be redundancy during data collection. Next, we simply clip buildings to AOI also.
Clipping by barriers
/* Grouping buildings by their zone (barrier polygons) */ islington_polygons_centroids_grouped AS ( SELECT islington_cluster_polygons_with_id.polygon_id as polygon_id , islington_polygons_centroids_clipped.geom as geom, islington_polygons_centroids_clipped.osm_id as osm_id FROM islington_polygons_centroids_clipped LEFT JOIN islington_cluster_polygons_with_id ON ST_Within(islington_polygons_centroids_clipped.geom, islington_cluster_polygons_with_id.geom) ),
Here we are simply giving barrier id to each centroid. This way we have ensured that now clustering happens inside segmented zones only and prevents buildings from across the barriers falling in same cluster.
Further Clustering using K-means
/* Clustering buildings centroids based on their zone (barrier polygons) */ islington_polygons_centroids_clustered AS ( SELECT ST_ClusterKMeans(geom, 7) over(PARTITION BY polygon_id) AS cid, geom, osm_id, islington_polygons_centroids_grouped.polygon_id FROM islington_polygons_centroids_grouped )
We use built-in functionality of postgis in order to cluster the centroids. This way we get the points clustered by distance.
Finally
/* Selecting and displaying clustered centroids */ SELECT * FROM islington_polygons_centroids_clustered ;
We get the clustered result.
If you are wondering how was the result here it is:
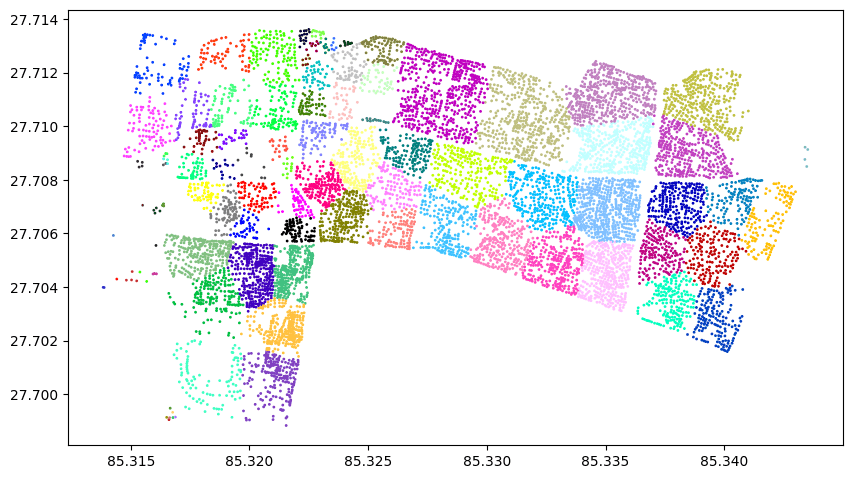
As you may see there is a lot of room for improvement. Things like:
- Dividing clusters into equal parts or into desired number of clusters
- Merging small clusters for balancing the workload could be done. The hackathon was two days long with around 10 hours coding time so, we did best we could do. I would love to know your views on this. My social media handles are here
Thank you for reading!
Share this on